
Kui Google tõi turule 6. märtsil Consent Mode nimelise uuenduse, nähti selles eelkõige võimalust siduda oma CMP (Consent Management Platform) Google’i teenustega (GA4, Ads). See tõi Eesti turule tormi, mida oleks võinud oodata juba peale GDPRi rakendumist 2018. aastal, mil kasutajatelt nõusoleku küsimine erinevate teenuste-tööriistade käivitamiseks muutus kohustuslikuks. Kuivõrd Eestis on selleteemaline järelevalve olnud pigem leebe, suhtusid enamik veebihalduritest sellesse kohustusse tagasihoidlikult, kuvades mittefunktsionaalseid nõusoleku küsimise aknaid või jättes need üleüldse implementeerimata jne. Oht jääda ilma oma andmetest Google’ist või müügitulemustest Google Adsis oli aga piisav motivaator, surumaks läbi muudatuse, mida Euroopa meist ootas viimased kuus aastat.
Kasutajatelt nõusoleku küsimine on tegevus, mis nõuab omajagu läbimõtlemist ja kompromisse. Kui teha seda tagasihoidlikult ning kasutajaid võimalikult vähe segades, tuleb leppida sellega, et valdav osa kasutajaid jätab nõusoleku andmata ning tekivad suured andmetühimikud. Kui küsida nõusolekut aga võimalikult silmapaistvalt (sisuliselt muutes lehe kasutamise ilma nõusoleku osas otsuse langetamist võimatuks), on võimalik läbimõeldud disainiga vältida andmetühimikke, ent selline lähenemine muudab lehe oluliselt vähem kasutajasõbralikumaks.
Käitumuslik modelleerimine ning selle komistuskivid
Üks põhiargumente, millega Google Consent Mode’i väljatöötamist põhjendas, oligi masinõppimise rakendamine, täitmaks andmetühimikke, mille tekitavad kasutajad, kes ei anna enda jälgimiseks nõusolekut. Eelkõige tähendab Consent Mode, et Google kogub kasutajatelt anonümiseeritud andmeid, mille abil modelleerida käitumuslikke- ning konversioonidega seotud andmeid.
Käitumuslik modelleerimine tähendab, et Google üritab hinnata põhilisi kasutaja- ning sessioonipõhiseid mõõdikuid, mis vastasel juhul läheksid kasutajate nõusoleku puudumisel kaduma. Kuigi tegu on tehisintellekti algelise vormiga, tähendab see siiski, et süsteem üritab olemasolevate andmete pealt pakkuda, kuidas andmetühimikke täita – kui hästi ta seda teeb, on vaieldav. Küll aga tuleb eraldi rõhutada andmekesksust – tegu pole lahendusega, mille saab ühekordselt seadistada ning tööle rakendada. Käitumusliku modelleerimise keskmes on andmed ning see suudab töötada juhul kui tal on piisavalt suured andmemahud, mille pealt oma ennustusi luua. Täpsemalt öeldes vajab käitumuslik modelleerimine:
- Vähemalt 1000 event-i päevas koos 7 päeva ajalooga.
- Vähemalt 1000 kasutajat päevas 28 järjestikuse päeva jooksul.
Tähelepanu tasub juhtida ka sellele, et 1000 kasutaja nõue tähendab, et vähemalt 1000 kasutajat on iga päev andnud nõusoleku enda jälgimiseks, nõusolekust keeldunud kasutajaid siia ei arvestata. 1000 eventi nõudmise puhul arvestatakse nii nõusoleku andnud kui ka sellest keeldunud kasutajaid. Nõusoleku andnud kasutajad moodustavad enamiku andmekogumist, kuna nende pealt püüab Google mõista, kuidas erinevad kasutajatüübid käituvad lehel. Väiksemal määral jälgib Google ka nõusolekust keeldunud kasutajaid, kuna nende andmetele tuginedes üritab ta oma hüpoteese valideerida, nägemaks, kas tema suurema andmehulga pealt tehtud ennustused pidasid paika või mitte.
Täpsustus: Consent Mode’i rakendamine ei tähenda veel sajaprotsendiliselt, et ettevõte vastab kõikidele GDPR’i nõuetele. Lisaks sellele, et GDPR sätestab veel mitmeid tingimusi ja nõudmisi, on ka Consent Mode’i metoodika ning selle vastavus GDPR’ile küsitav. Google ise väidab, et andmed, mida nad koguvad nõusolekut mitte andnud klientidelt, on anonümiseeritud ning agregeeritud, ent siinkohal on piir anonümiseerimise ning pseudonümiseerimise vahel siiski võrdlemisi õhuke.
Kas modelleeritud andmed on piisav tagatis, et Consent Mode kasutusele võtta?
Antud andmemahud võivad olla aga keeruliselt saavutatavad SME taseme ettevõtja jaoks. Kui võtta näiteks üks peamiselt Baltikumis tegutsev ettevõte (kel on nii e-pood kui füüsilised esindused), siis peale 9. märtsil seadistatud Consent Mode’i tekkis märgatav kukkumine igapäevases külastajate arvus. Kuna Consent Mode’i algoritmid vajavad modelleerimiseks aga vähemalt tuhandet consenti andnud kasutajat, tähendab see antud juhul, et selle kliendi puhul ei oleks võimalik modelleerimist rakendada. Täpsustuseks olgu öeldud, et antud kliendi puhul küsitakse nõusolekut lehe allservas, segades võimalikult vähe orgaanilist kasutajakogemust.
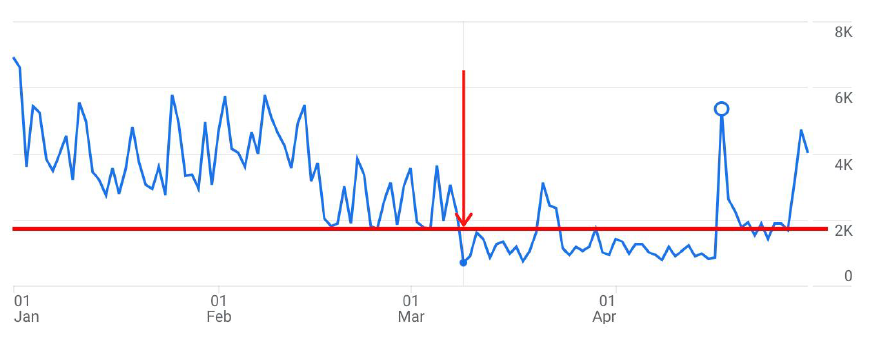
Valdav osa Eestis tegutsevatest SME-dest on seega sattunud dilemma ette:
- Kas seadistada Consent Mode korralikult, riskides andmekaoga ning seeläbi ka potentsiaalselt halvemate tulemustega Google Adsis?
- Kas jätta Consent Mode seadistamata ning leppida vähendatud funktsionaalsustega Google’i ökosüsteemis?
- Kas seadistada Consent Mode vaikimisi (kasutajate eest) nõusolekut andes, sealjuures riskides AKI kurja pilgu alla sattumisega?
Eelkõige tuleks lähtuda seadusandlikust perspektiivist – GDPR ning muud andmekaitsealased direktiivid on kasutusele võetud põhjusega. Kasutajate andmed on väärtuslik vara ning mitmed hiljutised andmelekked näitavad, et andmete väärkasutamine võib viia pigem suuremate probleemideni kui nende kasutuse reglementeerimine. Korrektne implementeerimine tekitab aga kaks probleemkohta – vähenenud andmed veebianalüütikas ning potentsiaalsed kehvem tulemuslikkus Google-i reklaamides. Neist viimane on puhtalt hüpoteetiline ning sõltub paljudest asjaoludest, sh. optimeerimismudelitest jm. Kui vaadata eelnevalt väljatoodud kliendi näidet, siis nende puhul ei ole võimalik täheldada mingeid märkimisväärseid languseid peale Consent Mode-i implementeerimist 9. märtsil.
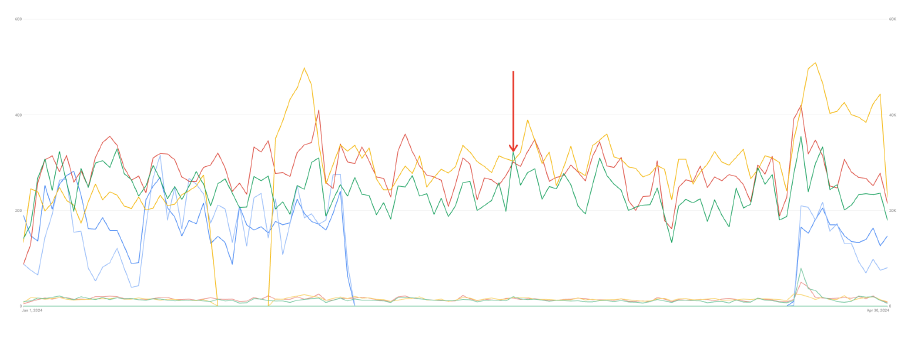
Kuigi ühe kliendi pealt on keeruline teha kindlalt paikapidavaid järeldusi, võib oletada, et ainsaks takistuseks Consent Mode’i kasutusele võtmisel jääbki andmekadu veebianalüütikas.
Mis on alternatiiv?
Google Analytics on saavutanud tänaseks pea monopoolse seisu veebianalüütika valdkonnas, omades pea 90% turuosa. Olukord, kus pea kogu turu poolt kasutatav tööriist pole enam töökindel, tekitab iseenesestmõistetavalt omajagu ärevust.
Küll aga tasub meeles hoida, et GA pole kaugeltki ainus tööriist veebianalüütika valdkonnas. Alternatiive on hulgaliselt ning osasid neist on võimalik kasutada ka teistsugustel alustel, sh ilma kasutajapoolset nõusolekut vajamata. Üheks näiteks sellistest tööriistadest on Matomo.
Matomo (endise nimega Piwik) on vabavaraline veebianalüütika tööriist, mis reklaamib end kui privaatsussõbralikumat alternatiivi. Kuigi kasutuseesmärk ning ka kasutajakogemus on GA’ga sarnased, erineb Matomo GA’st mitmel põhjusel:
- Andmeomand – kui GA puhul hoiustatakse andmeid Google’i serverites ning kogutud andmed kuuluvad ka neile, siis Matomo puhul kuuluvad kogutud andmed veebihaldurile. Lisaks on võimalik andmeid hoiustada oma serveris ning haldurile kuvatakse välja terviklikud (modelleerimata) andmed.
- Hoiustamine – kui GA puhul hoiustatakse andmeid ja kõike muud Google’i pilves, siis Matomo võimaldab installeerida tööriista kliendi enda serverisse. Kuigi Matomo pakub ka pilveteenust, on kohalikku serverisse paigaldamine andmeturvalisuse perspektiivist mõistlikum.
- Patenditud vs vabavaraline – Kui GA on eksklusiivselt Google’le kuuluv closed source tööriist, siis Matomo on täielikult vabavaraline, võimaldades koodi kohandada ning muuta vastavalt vajadusele.
- Omadused – kuigi algtasemel kasutades pole GA ning Matomo vahel suuri erinevusi võimalik täheldada, tuleb arvestada, et GA kuulub Google’i ökosüsteemi, tänu millele suudab ta väga töökindlalt koos töötada teiste Google’i teenustega.
Matomo üks põhieeliseid on asjaolu, et teatud tingimustel on teda võimalik jooksutada ilma kasutajapoolse nõusolekuta. Kuniks ei koguta isikustatavaid andmeid, andmeid ei otsekasutata reklaamimiseks vm kõrvalisel eesmärgil, neid ei jagata teiste keskkondade või tööriistadega, on võimalik Matomot seadistada nõusolekuta töötama. Sellisel juhul toimub kogu mõõtmistöö ilma küpsisteta, ent arvestada tuleb teatud mõõnsustega – küpsistevaba track’imine tähendab, et platvormil on keerulisem hinnata unikaalseid mõõdikuid. See tähendab, et unikaalsed külastajad jm analoogsed mõõdikud võivad olla ebatäpsed.
Mis on parim lahendus?
Kui rääkida Consent Mode’ist, tekib turundajatel tihtipeale väärarusaam – arvatakse, et räägitakse nõudest kasutajatelt nõusolekut küsida, kuigi tegelikult oli Consent Mode’i näol tegu lihtsalt Google’i poolse lahendusega olukorrale, kus kasutajapoolne nõusoleku küsimine hakkas liiga tegema GA4’s olevate andmete kvaliteedile. Asjaolu, et Consent Mode’i “kohustuslikuks muutmine” pani veebihaldureid mõtlema nõusoleku küsimise seadistamisele, ent GDPR seda ei teinud, peegeldab pigem turu üldist leebet suhtumist andmete kogumisse ja töötlemisse.
Paradoksaalsel kombel tekkiski seeläbi olukord, kus Google’i pakutud lahendus hoopis tekitas Eesti turul probleemi. Selleks, et lahendust kasutada, pidi seadistama ka nõusoleku küsimise ning leppida andmekaduga, ent Google’i lahendus ei suuda Eesti turu mastaapides kasulik olla.
Lahendusi otsides tuleks eelkõige lähtuda seadusandlusest, seejärel riskidest ja võimalustest. Kui GDPR’i poolne nõue on küsida kasutajatelt nõusolekut nende jälgimiseks, tasub seda ka teha. Kui Google’i poolne nõue on rakendada Consent Mode’i, tasub ka seda teha. Vältimaks aga andmekadu, tasub kaaluda Matomo või mõne sarnase tööriista kasutuselevõttu kõrvalise tööriistana. Kuivõrd Matomo, Plausible jm tööriistad on mõnevõrra algelisemad võrreldes GA4’ga, on mõistlik neid kasutada paralleelselt GA4’ga. See võimaldab kasutada GA4’d, et analüüsida kvantitatiivseid näitajaid (mis lehtedelt kasutajad lahkuvad, põrke- ning konversioonimäärad jne) ning jagada andmeid teiste Google’i teenuste ja tööriistadega (GSC, Ads). Matomo saab töötada kui tööriist andmekvaliteedi valideerimiseks, võimaldades hinnata kvantitatiivseid mõõdikuid (külastuste koguarv), mis – nagu ilmestab ka eelnevalt mainitud kliendi näide – võivad olla oluliselt erinevad GA’s olevatest vastavatest mõõdikutest.
Date | Matomo user count | GA user count |
| 15.03.2024 | 2495 | 1322 |
| 16.03.2024 | 2561 | 984 |
| 17.03.2024 | 2780 | 1185 |
| 18.03.2024 | 2244 | 754 |
| 19.03.2024 | 3776 | 1060 |
| 20.03.2024 | 4313 | 1595 |
| 21.02.2024 | 9221 | 1811 |